执行摘要
这期播客将 OpenAI GPT Image 2 描述为从审美型图像生成转向更结构化视觉推理的变化。讨论强调,模型不只是生成更好看的图片,也在文字渲染、对象摆放、构图控制和知识密集型视觉内容方面进步。
讨论强调了一个重要使用模式:图像生成正在成为 ChatGPT 内的生产力界面,而不只是新奇功能。嘉宾把采用增长与内部演示幻灯片、教育图解、灵感图混合和更忠实的视觉草稿等实际场景联系起来。嘉宾还提到 ChatGPT 每周生成超过 15 亿张图片,并且发布后使用量增长超过 50%。
对构建者来说,最有用的想法是从视觉生成到可执行工作流的桥接。图像模型可以起草概念、布局或素材表,而编程工具和代理式工作流可以把这些输出转化为界面、原型或结构化应用产物。
对话也指向基于思考的图像工作流。在这种模式下,系统可以围绕上下文推理、搜索或检查支持材料,然后渲染更有依据的视觉结果,而不是把图像生成当作单轮提示到图片的终点。
关键要点
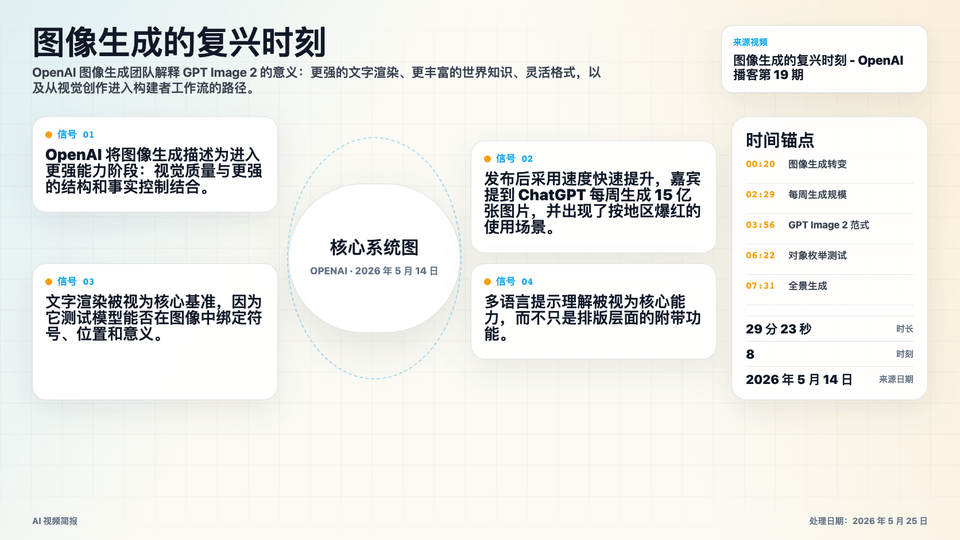
- OpenAI 将图像生成描述为进入更强能力阶段:视觉质量与更强的结构和事实控制结合。
- 发布后采用速度快速提升,嘉宾提到 ChatGPT 每周生成 15 亿张图片,并出现了按地区爆红的使用场景。
- 文字渲染被视为核心基准,因为它测试模型能否在图像中绑定符号、位置和意义。
- 多语言提示理解被视为核心能力,而不只是排版层面的附带功能。
- 视频梳理了模型从 DALL-E 3 到早期图像版本,再到 GPT Image 2 能处理更大对象枚举测试的演进。
- 任意宽高比和 360 度全景输出很重要,因为它们把图像生成变成格式灵活的生产工具。
- Token 效率被作为产品约束提出:只有在生成速度仍适合日常工作流时,更高保真度才有实际价值。
- 参考图像和 ChatGPT 记忆让图像生成更具上下文感知能力,可改善风格匹配和个性化。
- 教育图解、内部演示幻灯片、线框图和精灵图表,比通用插画输出更适合作为构建者场景。
- 思考层级生成将图像模型重新定义为规划系统:在生成最终视觉结果前可以收集上下文。
构建者启发
- 围绕可复用产物设计图像工作流:图解、布局、素材表、幻灯片、产品样机和 UI 起点。
- 当输出需要成为应用界面而不只是静态素材时,把图像生成与编程工具配对。
- 让提示保持足够开放,使具备思考能力的模型能在渲染前推理、检查上下文并自我修正。
- 提供对有意不完美和风格具体性的控制;许多有用输出并不应该显得过度精修。
- 围绕生成图像构建编辑和布局工作流,因为企业团队需要修改路径,而不是一次性导出。
- 把视觉生成视为多模态生产系统的一部分,它可以结合文件、参考、文本上下文和代码执行。
待验证事项
- GPT Image 2 的能力在 ChatGPT 套餐、API 和思考型界面中的表现是否一致。
- 100 对象枚举基准在不同提示、语言、风格和密集构图下的稳健性。
- 科学和教育图解在没有专家人工审查时,能多频繁保持事实准确。
- 基于思考的图像生成相对标准生成的延迟和成本权衡。
- 记忆和个性化是否能改善专业工作流,同时不引入不必要的隐私或品牌一致性风险。