Executive Summary
The podcast frames OpenAI's GPT Image 2 as a shift from aesthetic image generation toward more structured visual reasoning. The discussion emphasizes that the model is not only producing more attractive pictures; it is improving at text rendering, object placement, compositional control, and knowledge-heavy visuals.
The discussion highlights a major usage pattern: image generation is becoming a productivity surface inside ChatGPT, not just a novelty. The speakers connect adoption growth to practical use cases such as internal presentation slides, educational diagrams, inspiration-image remixing, and more faithful visual drafting. The speakers also cite more than 1.5 billion images generated each week in ChatGPT and more than 50 percent usage growth after launch.
For builders, the most useful idea is the bridge from visual generation to executable workflows. Image models can draft the concept, layout, or asset sheet, while coding tools and agentic workflows can turn those outputs into interfaces, prototypes, or structured application artifacts.
The conversation also points toward thinking-based image workflows. In that mode, the system can reason over context, search or inspect supporting material, and then render a more informed visual result instead of treating image generation as a single-turn prompt-to-picture endpoint.
Key Takeaways
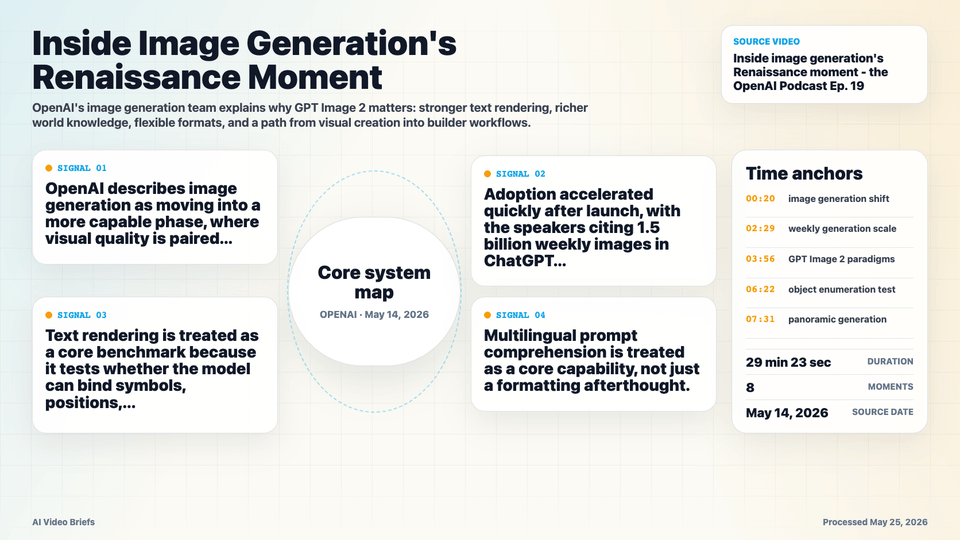
- OpenAI describes image generation as moving into a more capable phase, where visual quality is paired with stronger structural and factual control.
- Adoption accelerated quickly after launch, with the speakers citing 1.5 billion weekly images in ChatGPT and region-specific viral use cases.
- Text rendering is treated as a core benchmark because it tests whether the model can bind symbols, positions, and meaning inside the image.
- Multilingual prompt comprehension is treated as a core capability, not just a formatting afterthought.
- The video traces a model progression from DALL-E 3 through earlier image releases toward GPT Image 2 handling much larger object enumeration tests.
- Arbitrary aspect ratios and 360-degree panoramic outputs matter because they turn image generation into a format-flexible production tool.
- Token efficiency is presented as a product constraint: better fidelity is only useful if generation speed remains practical for everyday workflows.
- Reference images and ChatGPT memory make image generation more context-aware, which can improve style matching and personalization.
- Educational diagrams, internal presentation slides, wireframes, and sprite sheets are stronger builder use cases than generic illustrative output.
- Thinking-tier generation reframes the image model as a planning system that can gather context before producing the final visual.
Builder Implications
- Design image workflows around reusable artifacts: diagrams, layouts, asset sheets, slides, product mockups, and UI starting points.
- Pair image generation with coding tools when the output needs to become an application surface, not just a static asset.
- Keep prompts open enough for thinking-enabled models to reason, inspect context, and self-correct before rendering.
- Expose controls for intentional imperfection and style specificity; many useful outputs are not supposed to look hyper-polished.
- Build editing and layout workflows around the generated image, because enterprise teams will need revision paths, not one-shot exports.
- Treat visual generation as part of a multimodal production system that can combine files, references, text context, and code execution.
Things to Verify
- How consistently GPT Image 2 capabilities perform across ChatGPT plans, APIs, and thinking-enabled surfaces.
- The robustness of the 100-object enumeration benchmark across prompts, languages, styles, and dense compositions.
- How often scientific and educational diagrams remain factually accurate without manual expert review.
- The latency and cost tradeoffs of thinking-based image generation compared with standard generation.
- Whether memory and personalization improve professional workflows without creating unwanted privacy or brand-consistency risks.